

{kind=link}
This weblog is collectively written by Md Rahman, Arkaprabho Ghosh, Navin Bilwar, and Desh Shukla.
Govt abstract
Cisco IT not too long ago evaluated fine-tuning embedding fashions utilizing NVIDIA Nemotron RAG fine-tuning recipe as a part of an effort to enhance retrieval accuracy for domain-specific enterprise knowledge. The target was to not redesign current retrieval-augmented era (RAG) techniques, however to grasp whether or not focused embedding fine-tuning might materially enhance semantic search high quality with affordable effort and quick turnaround. By this experiment, Cisco was in a position to validate firsthand that embedding fine-tuning, mixed with artificial knowledge era, can ship measurable accuracy positive factors inside a short while body. The experiment additionally demonstrated robust time-to-value, enabling speedy iteration and clear efficiency indicators with out lengthy coaching cycles or in depth guide labeling. The decreased turnaround of just a few days to grasp the rapid advantages was a key consequence of this collaboration.
The embedding mannequin coaching and analysis workflow was executed on Cisco AI PODs working Cisco UCS 885A infrastructure powered by NVIDIA HGX platform.
Downside assertion
Previous to conducting this experiment, Cisco had performed related embedding fine-tuning experiments utilizing earlier era fashions and smaller scale infrastructure. These prior efforts required important guide tuning of hyperparameters resembling batch dimension and variety of epochs, and outcomes had been usually tough to stabilize. Iteration cycles had been lengthy, making it difficult to discover totally different configurations or scale experiments. Regardless of some localized enhancements, key phrase search remained obligatory for a lot of domain-specific retrieval situations. There was additionally no standardized, end-to-end workflow that engineering groups might execute rapidly and consider persistently throughout runs. Usually, these efforts would take weeks to months of guide effort for unsure positive factors.
How the high-quality‑tuning went and time to worth
On this experiment, Cisco used the NVIDIA NeMo Retriever embedding finetuning recipe, leveraging artificial knowledge era to supply coaching indicators from current corpora. The recipe runs by 5 distinct levels: artificial knowledge era (SDG), knowledge preparation with hard-negative mining, contrastive fine-tuning, BEIR analysis, and ONNX mannequin export. The workflow was in a position to run end-to-end efficiently. All experiments ran on a single NVIDIA H200 143 GB GPU hosted inside Cisco AI Pods constructed on Cisco UCS 885A techniques. Finetuning runs accomplished inside hours of coaching time, enabling speedy experimentation throughout a number of dataset sizes and configurations. Using artificial knowledge era eradicated the necessity for guide labeling, considerably lowering overhead. This strategy allowed Cisco to iterate rapidly, observe efficiency traits early, and validate whether or not embedding fine-tuning was value additional funding. The general time-to-value was considerably shorter than earlier efforts, with significant insights gained after solely a small variety of runs.
The five-stage pipeline structure:
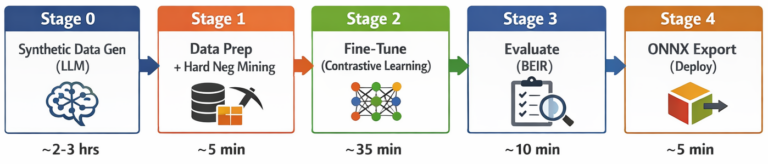 Timings based mostly on ~925 paperwork / ~9,200 QA pairs / ~7,800 coaching examples on a single NVIDIA H200 GPU working on Cisco AI Pods with Cisco UCS 885A infrastructure. Precise period scales with knowledge quantity.
Timings based mostly on ~925 paperwork / ~9,200 QA pairs / ~7,800 coaching examples on a single NVIDIA H200 GPU working on Cisco AI Pods with Cisco UCS 885A infrastructure. Precise period scales with knowledge quantity.
Accuracy positive factors noticed
Throughout a number of experiments, the outcomes confirmed constant, measurable enhancements. Superb-tuning the NVIDIA 1-billion-parameter NV-EmbedQA mannequin on artificial domain-specific knowledge yielded positive factors throughout all retrieval metrics, with NDCG@1 positive factors of +7.1 to +7.3 absolute factors (+9.9% to +11.1% relative). Recall@10 improved by as much as +6.8 factors (+8.5%), and MAP@10 by as much as +6.5 factors (+9.7%). Utilizing an on-premise 120B-parameter LLM for artificial knowledge era, the whole pipeline ran with zero exterior API prices and with the information staying fully on prem ensured knowledge privateness. These positive factors held at the same time as dataset dimension elevated and retrieval duties turned tougher. Importantly, enhancements had been noticed on domain-specific queries that beforehand carried out poorly with base embedding fashions. Whereas these outcomes symbolize an preliminary baseline relatively than a completely optimized consequence, they supplied robust affirmation that embedding fine-tuning can materially enhance retrieval high quality for enterprise-specific knowledge.
Abstract of experiments
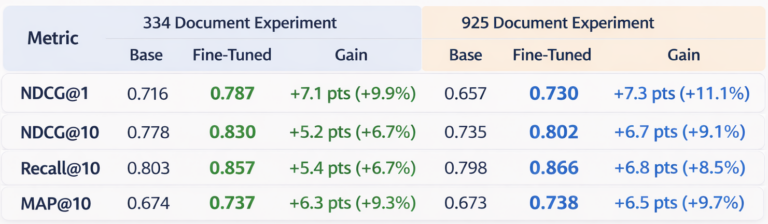 Desk 1. Retrieval efficiency comparability between the bottom embedding mannequin and the contrastively fine-tuned mannequin throughout two dataset sizes (334 and 925 paperwork). Superb-tuning persistently improves rating high quality throughout all BEIR analysis metrics.
Desk 1. Retrieval efficiency comparability between the bottom embedding mannequin and the contrastively fine-tuned mannequin throughout two dataset sizes (334 and 925 paperwork). Superb-tuning persistently improves rating high quality throughout all BEIR analysis metrics.
Key Observations:
- Superb-tuning persistently improved retrieval high quality throughout all metrics.
- NDCG@1 confirmed the most important enchancment in top-level relevance.
- Positive aspects had been steady throughout the 2 dataset sizes (334 and 925 paperwork).
- Improved Recall@10 and Map@10 positive factors indicative of higher protection and rating than the bottom embedding mannequin.
What stunned us
Essentially the most sudden discovering was how rapidly the recipe delivered actionable outcomes. Inside a couple of days of beginning the experiment, we had measurable accuracy enhancements — a stark distinction to earlier efforts that took weeks to months. The artificial knowledge era strategy produced coaching indicators of adequate high quality to drive significant positive factors with no single manually labeled instance. We had been additionally stunned by how properly the enhancements generalized throughout question sorts, together with the rare-token identifier queries that had traditionally been the weakest level for semantic search.
Subsequent steps with engagement
Constructing on these outcomes, Cisco will proceed working with NVIDIA to systematically push accuracy additional. The subsequent section of labor will focus on:
- Utilizing a set analysis set throughout runs in order that metrics might be straight comparable
- Tuning the educational fee (making an attempt default, half, and double) and rising epochs from 3 to five
- Scaling coaching knowledge to ~100K QA pairs to search out the saturation level for the area
- Utilizing a bigger or higher-quality LLM for artificial knowledge era to enhance QA pair constancy
- Making use of 10% warmup with cosine decay for extra steady convergence
- Rising hard-negative mining from 5 to 10 negatives per question for a stronger contrastive sign
- Refining artificial knowledge era prompts to raised emphasize uncommon and domain-specific phrases — bug IDs, product identifiers, firmware variations — the place base fashions wrestle most
- Exploring chunk-aware coaching: utilizing actual doc chunks from a manufacturing vector database because the retrieval corpus, producing questions towards these chunks through the LLM, and mapping every query to its constructive chunk and hard-negative chunks — coaching the mannequin on the identical knowledge distribution it will encounter in manufacturing, the place solutions could also be buried in longer textual content and chunking methods will range
Long term, the engagement will broaden to incorporate re-ranker fine-tuning and broader retrieval optimization as a part of a full end-to-end RAG enchancment effort.
Worth of the fine-tuning embedding mannequin
This experiment helps that leveraging a fine-tuning embedding mannequin can speed up time to manufacturing by offering a validated, end-to-end fine-tuning workflow that delivers measurable enhancements in days relatively than months. The concepts and findings from this work are actively shaping the recipe’s evolution, whereas Cisco positive factors early entry to a maturing pipeline that shortens the trail from experimentation to manufacturing. The work additionally demonstrates how Cisco AI Pods based mostly on Cisco UCS 885A techniques and NVIDIA H200 GPUs can present an efficient enterprise infrastructure basis for speedy embedding mannequin adaptation.
Key fine-tuning embedding mannequin advantages for companies
- Defend proprietary knowledge (on-premises execution)
- Cut back assist prices (quicker decision, fewer escalations)
- No cloud API dependency (zero exterior prices)
- Quick time-to-value (full end-to-end pipeline — all 5 levels together with SDG, mining, coaching, analysis, and export — completes in 2-5 hours on a single GPU)
Key fine-tuning embedding mannequin advantages for builders
- No guide annotation required (artificial knowledge era)
- Modular, hackable structure (5 distinct levels: SDG → Knowledge Prep → Superb-Tune → Consider → Export)
- Manufacturing-ready outputs (ONNX export)
- Constructed-in analysis (BEIR — Benchmarking Data Retrieval — framework)
- Arduous adverse mining included (computerized high quality enhance)
Get began
The fine-tuning recipe for Llama Nemotron Embed 1B mannequin is out there now as an entire, production-ready pipeline. Whether or not you’re constructing enterprise search, RAG functions, or domain-specific retrieval techniques, this recipe supplies a transparent path from uncooked paperwork to deployed, domain-adapted embeddings.
Able to fine-tune your individual embedding mannequin?
👉 Discover the Nemotron Embed Superb-Tuning Recipe on GitHub